목차
파이썬의 라이브러리 중 판다스의 데이터프레임은 데이터 분석을 위해 꼭 기억해야 할 부분이 있습니다. 특히 전처리나 필요한 부분의 데이터만 별도로 추출하는 기능은 꼭 알아두어야 합니다. 데이터 추출의 기본 기능은 아래 포스팅에 자세히 설명되어 있으니 참고하시면 됩니다. 본 포스팅에서는 특정 조건에 대한 데이터 추출 방법에 대해 설명하겠습니다.
https://lifelong-education-dr-kim.tistory.com/entry/Pandas-데이터프레임-기본-인덱싱-이론과-방법
Pandas 데이터프레임 기본 인덱싱 이론과 방법
데이터 분석을 위해 파이썬을 사용하는 데 있어 판다스(pandas)는 핵심이라 할 수 있습니다.. 데이터를 불러와 전처리를 수행하고 데이터 관계 확인 및 데이터 가시화까지 모두 지원되기 때문입니
lifelong-education-dr-kim.tistory.com
1. 조건 추출(boolean indexing)의 개요
조건 추출의 명확한 명칭은 boolean indexing입니다. 데이터를 필터링하기 위해 boolean vector들을 사용합니다. True와 False가 바로 boolean vector입니다. 조건추출의 기본은 어떠한 조건이 True인지 False인지를 파악하고 이들의 조합을 통해 필요한 데이터만 취득하는 것입니다. vector들의 조작자로는 합집합/or를 의미하는 '|', 교집합/and를 위한 '&' 그리고 not을 뜻하는 '~'가 있습니다.
2. Boolean vector 만들기와 mask
두 번째 주제를 위해 간단한 데이터 셋을 만들어 보겠습니다. 10개의 행과 4개의 열을 갖는 데이터 셋을 만들고 숫자는 랜덤함수를 사용했습니다. 소수점 자리수를 2로 하여 데이터를 짧게 했습니다.
df = pd.DataFrame(np.round(np.random.randn(10, 4), 2), columns=['A', 'B', 'C', 'D'])

데이터 셋에서 조건을 달아서 boolean vector로 변경해 보겠습니다. 조건은 A열에 있는 데이터가 0이상인지를 확인하는 것입니다. 구문은 df['A'] > 0 입니다. 캡처 시 아래로 길어지지 않게 list(df['A']>0) 구문으로 리스트화하였습니다.

df에서 A열을 살펴보면 1행과 마지막 행만 양수입니다. 조건에 대한 결과가 아주 잘 나왔습니다. 이번에는 A열이 음수이면서 B열도 음수인 조건을 만들어 보겠습니다. (df['A']<0) & (df['B'] < 0) 구문을 사용하면 되며, & 조작자를 사용할 때는 반드시 ()로 하나의 조건을 묶어줘야 구문에러가 발생하지 않습니다.

여러 가지 원하는 조건들을 조합하여 boolean vector를 구할 수 있습니다. 이제 이렇게 얻은 boonean vector를 mask로 만들어 사용하겠습니다. 결국 조건을 만들어 boolean vector를 만드는 이유는 조건에 부합하는 데이터만 추출하여 사용하는 데 있습니다. mask는 필터와 비슷한 용어로 걸러주는 역할을 합니다.
mask1 = (df['A']<0) & (df['B'] < 0)

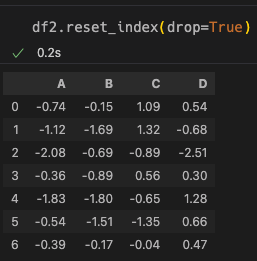
조건문을 mask1에 입력하고 데이터프레임에 입력하면 False행은 걸러지고 True행만 남는 것을 확인할 수 있습니다. 인덱스에는 mask1에서 False에 해당하는 index 번호가 삭제되었습니다. 이렇게 조건을 통해 데이터를 추출하면 꼭 해야 하는 일이 있습니다. index 번호가 중간중간 빠져 있기 때문에 추후 데이터 호출을 할 때 에러가 발생될 수 있습니다. 초기 데이터셋에서 조건에 맞게 데이터를 추출했다면 df.reset_index(drop=True)를 이용하여 index를 리셋해야 합니다.
3. reference 파일을 이용한 데이터 feature 선정하기
조건추출은 데이터 전처리 시 사용해야 하는 데이터만 남기는 데 사용합니다. 이번에는 데이터 전처리 외의 사용에 대해 설명하겠습니다. 수많은 feature를 갖는 데이터셋이 있다고 가정하겠습니다. 여기서는 1000개 정도로 한정하겠습니다. 1000개의 feature(열)에 데이터수(행)가 수십만 개라 할 때 모든 데이터셋을 핸들링한다면 리소스 낭비가 될 것입니다. 데이터 분석이나 알고리즘 개발에 꼭 필요한 feature가 15개라고 하면 나머지 985개는 필요 없는 데이터가 됩니다.
엑셀파일을 이용하여 위와 같은 형태로 feature열에는 모든 feature를 집어넣고 Use에 0, 1, 2와 같이 표기합니다. 사용여부만 걸러낼 때는 0, 1만 사용하면 됩니다. 사용 유무와 feature의 grouping을 위해서는 2, 3, 과 같은 숫자를 같이 사용하면 됩니다. 저장 시에는 'ref.xlsx'명으로 저장 후 파이썬에서 ref_col = pd.read_excel('ref.xlsx') 구문으로 불어옵니다. 만일 ref.xlsx의 경로가 다른 곳에 있다면 '\\경로\\ref.xlsx' 로 인풋인자를 바꿔주면 됩니다. 사용을 위한 mask와 group mask 구문은 아래처럼 만들어 줍니다.
Use_mask = df['Use'] == 1
Group_mask = df['Use'] == 2
마스크를 데이터프레임에 대입하여 필요한 칼럼명만 취득합니다.
use_col = list(df[Use_mask]['Feature'].values)
gourp_col = list(df[Group_mask]['Feature'].values)
df에 마크스를 적용하게 되면 마크킹 된 데이터만 남습니다. 이때 feature에 있는 값만 취하는 겁니다. list()를 사용하여 array 타입에서 리스트 타입으로 변경하였습니다. 칼럼이 1000개인 데이터 셋(df)에 use_data = df[use_col]을 사용하게 되면 필요한 데이터만 뽑아서 사용할 수 있습니다. 해당 내용은 아래 링크에 자세히 설명되어 있으니 참고하시면 됩니다.
https://lifelong-education-dr-kim.tistory.com/entry/Python-pandas로-xlsx-cdv-불러오기
Python pandas로 csv, xlsx 불러오기
현장에서 사용하는 데이터 분석을 위해서는 현장에서 얻은 데이터의 전처리 업무가 데이터 분석의 약 80%이상을 차지한다 해도 과언이 아니다. 인터넷상으로 구한 데이터셋은 일정한 포맷이 있
lifelong-education-dr-kim.tistory.com
4. 마치며
지금까지 boolean vector에 대해 알아보고 이를 이용한 데이터 인덱싱하는 방법을 정리하였습니다. 데이터 조건 추출 시 꼭 mask를 사용할 필요는 없습니다. 마스크에 입력되는 구문을 바로 사용해도 됩니다. 다만 조건들이 많아지고 여러 데이터셋을 사용할 경우에는 mask를 사용하면 편리합니다. 마지막에는 조건 추출을 이용한 feature선정하는 법을 같이 설명드렸습니다.



