목차
파이썬 프로그래밍을 데이터 분석에 사용하다 보면 데이터를 가시화해야 하는 경우가 있습니다. 일반적으로 많이 사용하는 함수는 2차원의 직선을 그려주는 plot일 겁니다. 사실 이는 직선이라기보다는 데이터의 점들을 잇는 선이라고 표현하는 것이 더 맞을 겁니다. 오늘은 또 다른 가시화 함수인 scatter(산점도)의 각 인자들이 어떻게 사용되는지 알아보겠습니다.

1. 산점도(scatter plot)란?
산점도(Scatter plot)는 두 변수 간의 관계를 시각화하기 위해 사용되는 그래프입니다. 산점도는 수치형 데이터로 이루어진 두 변수의 값들을 좌표 평면 상에 점으로 나타내며, 각 점은 변수 간의 상대적인 관계를 보여줍니다.
일반적으로 x축과 y축은 서로 다른 변수를 나타냅니다. 각 점의 위치는 해당 변수들의 값을 표시하며, 점의 위치와 분포 패턴을 통해 변수 간의 관계를 파악할 수 있습니다. 산점도는 데이터의 분산, 집중도, 군집 등을 시각적으로 확인할 수 있어 데이터의 패턴을 탐색하는 데 유용합니다. 아래와 같은 질문에 대답하기 위해 산점도의 가시화를 사용할 수 있습니다.
- 두 변수 간에 어떤 종류의 상관관계가 있는가?
- 두 변수 간에 어떤 패턴이 있는가?
- 어떤 변수 값에 따라 다른 변수의 값이 어떻게 변하는가?
- 데이터가 군집을 이루는가?
산점도는 데이터 분석, 회귀 분석, 이상치 탐지 등 다양한 분야에서 널리 사용되며, 데이터의 시각적인 특성을 파악하는 데 도움을 줍니다.
2. Pyplot.scatter() 사용법
파이썬 프로그래밍에서 scatter함수는 plot 함수와 유사한 방법으로 사용할 수 있습니다.
import matplotlib.pyplot as plt
plt.scatter(x, y, c, s, marker, cmap, alpha)
각 인자에 대한 설명입니다.
입력값의 타입: scatter 함수는 x와 y 인자로 배열 또는 값들을 받습니다. 일반적으로 NumPy 배열이나 Python 리스트와 같은 순차적인 데이터 타입을 사용합니다.
크기와 색상 인자: s와 c 인자는 각각 마커의 크기와 색상을 지정합니다. 이들 인자는 스칼라 또는 배열을 허용합니다. 스칼라 값을 사용하면 모든 마커가 동일한 크기 또는 색상을 가지게 되고, 배열을 사용하면 각 마커마다 다른 크기 또는 색상을 지정할 수 있습니다. 크기 배열(s)은 음수 값이나 0은 허용되지 않으며, 색상 배열(c)은 0에서 1 사이의 값 또는 0과 1 사이의 RGB 튜플 값을 사용해야 합니다.
마커 모양: marker 인자는 마커의 모양을 지정합니다. 예를 들어, 'o'는 원, '^'는 삼각형, 's'는 사각형 등으로 사용할 수 있습니다. 기본값은 'o'입니다.
색상 맵: cmap 인자를 사용하여 색상 맵을 지정할 수 있습니다. 색상 맵은 값의 범위를 색상으로 매핑하는 데 사용됩니다. 예를 들어, 'viridis', 'jet', 'coolwarm' 등의 색상 맵을 사용할 수 있습니다.
투명도: alpha 인자를 사용하여 마커의 투명도를 지정할 수 있습니다. 0은 완전히 투명하고 1은 완전히 불투명함을 의미합니다.
3. Scatter() 함수 사용 예제 코드
위에서 설명한 인자들의 값이 입력된 예제코드는 다음과 같습니다.
import matplotlib.pyplot as plt
import numpy as np
# 데이터 생성
np.random.seed(1)
x = np.random.rand(100)
y = np.random.rand(100)
colors = np.random.rand(100)
sizes = 1000 * np.random.rand(100)
# scatter 그래프 그리기
plt.scatter(x, y, c=colors, s=sizes, alpha=0.5, cmap='viridis')
# 축 레이블과 제목 설정
plt.xlabel('X')
plt.ylabel('Y')
plt.title('Scatter Plot')
# 컬러바 추가
plt.colorbar()
# 그래프 보이기
plt.show()
'x'와 'y'의 데이터를 각각 100개씩 랜덤으로 생성하고, 색상과 산점의 크기 또한 같은 방식으로 지정한 산점도를 그리려고 했습니다. 투명도는 0.5의 값으로 하였고 색상맵으로는 'viridis'를 사용했습니다. 그 아래 세팅은 그래프를 세팅하는 데 사용했습니다.
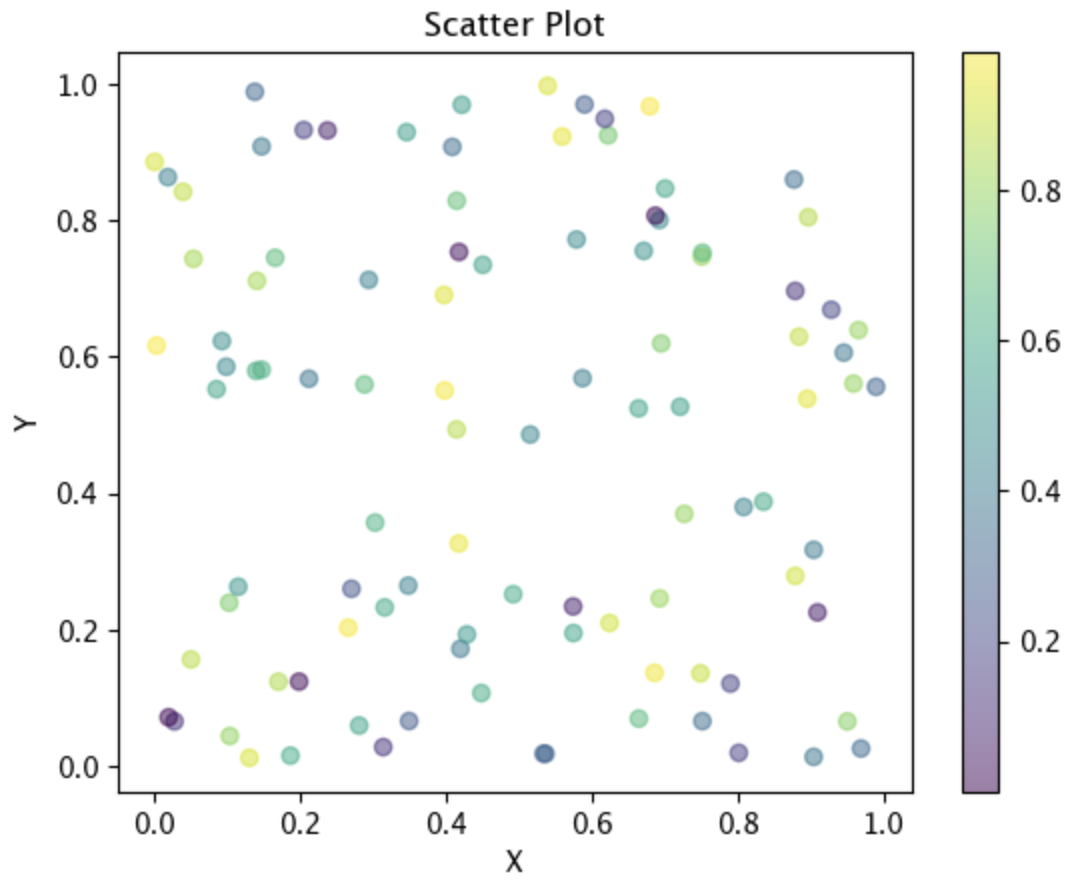
두 변수의 관계를 확인할 때 산점도를 사용하는데, 위의 경우는 분포가 퍼져있는 것으로 상관성이 없다고 볼 수 있습니다. 만일, 'y=x'와 같은 직선 형태의 그래프가 그려진다면, 밀접한 관계가 있다고 판단할 수 있습니다.
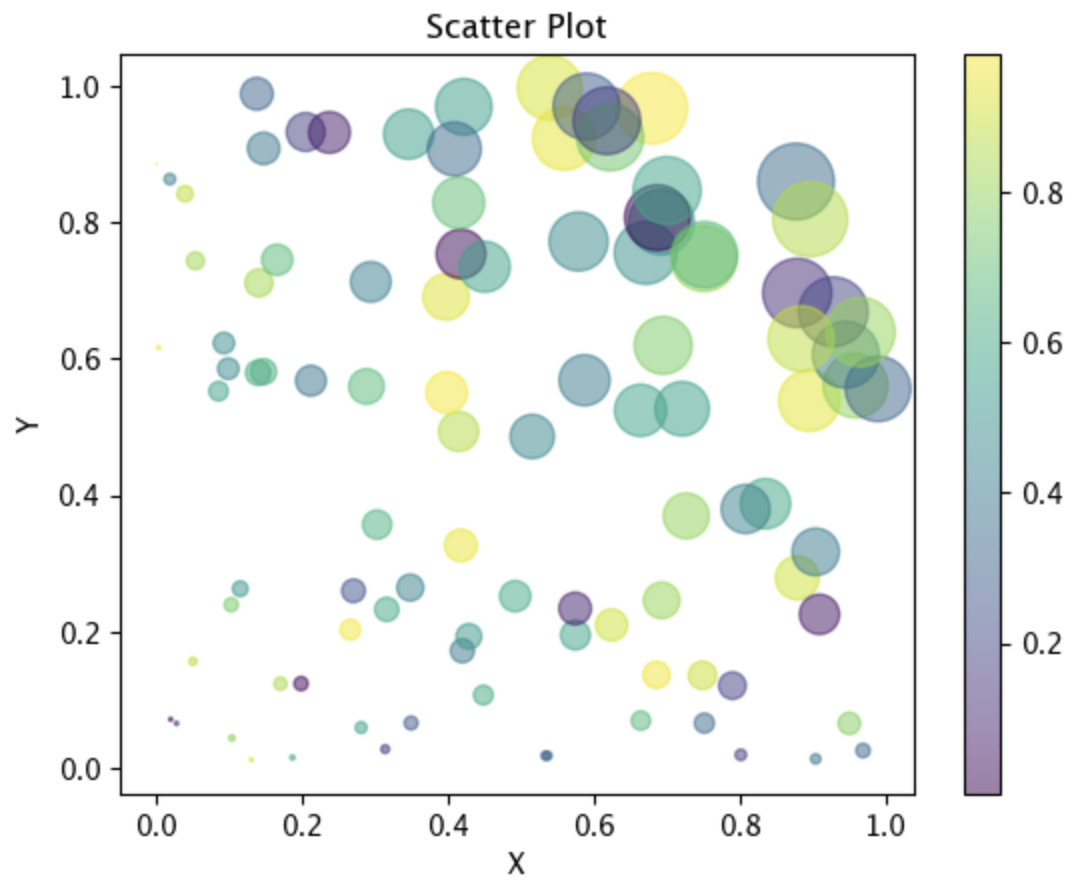
Scatter함수의 size는 그 위치에 해당하는 값에 대응하게 넣는 것이 일반적입니다. 위의 코드 중 sizes의 값을 아래와 같이 바꾸는 것처럼 보여주고 싶은 값에 해당하도록 설정해 주는 것이 좋습니다. 여기서는 x와 y의 값이 커질수록 원의 크기를 크게 해 주겠다는 의미입니다.
# sizes = 1000 * np.random.rand(100)
sizes = 1000*(x*y)
4. 마치며
파이썬의 가시화 함수 중 scatter는 두 개 변수 간의 관계를 가시적으로 확인하기 위해서 사용할 수 있습니다. 그를 위한 함수의 인자들에 대해 설명을 하였고, 예제 코드를 활용에 그 사용법을 확인해 보았습니다. 더 많은 응용이 있기 때문에 오늘의 기본 사용법을 잘 익혀두길 바랍니다.



