목차
회사업무를 하다 보면 여러 개의 엑셀 파일을 취합해야 하는 경우가 많이 생긴다. 특히나 데이터 분석에 필요한 데이터를 저장할 때 달, 주, 일, 시간 등 일정 단위로 파일을 생성하기 때문에 전체 기간의 분석을 위해서 데이터 취합은 필수 과정이 된다. 주제는 하나의 파일로 취합한다고 했지만 여러 개의 파일을 불러와서 하나의 데이터 프레임으로 만든다고 얘기하는 것이 더 맞을 듯하다.
우선 여러 개의 데이터 파일을 취합하는데 앞서 늘 그렇듯 여러 개의 데이터 파일을 생성하는 것부터 포스팅 내용을 시작하려 한다. 취합 관련 내용은 아래에 있으니 그 부분만 필요한 분들께서는 해당 내용을 스킵해도 된다.(3. 폴더/파일명을 이용한 여러개의 파일의 데이터 취합하기에서 내용 확인) 매 포스팅마다 데이터 생성하는 방법을 우선 소개하는 데는 예제 코드에 걸맞은 데이터가 없는 것도 이유이지만 소개 내용 안에 몇몇 기능들도 살펴보자는 목적이 있다.
1. 데이터 파일 생성 : 주요 라이브러리 - Pandas, Numpy, Random, String
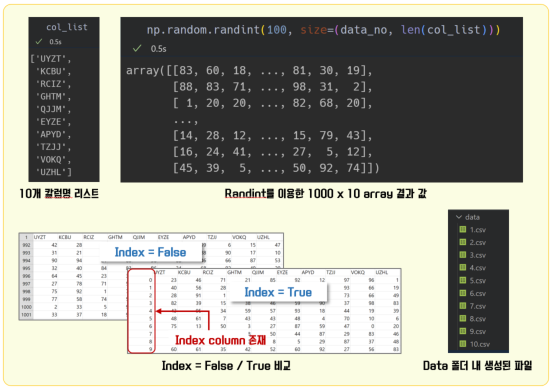
10개의 칼럼과 1000개의 행으로 구성된 엑셀파일(csv) 10개를 생성시켜 보자. 주요 라이브러리는 pip install 을 통해 미리 설치하고 아래와 같이 import를 하자.
import pandas as pd
import random
import string
import numpy as np
랜덤으로 칼럼명을 생성하지만 매 파일마다 칼럼명이 변경되면 안 되니 초기에 칼럼명을 생성하게 한다. col_no 변수로 총 몇 개의 칼럼을 생성할 것인지에 대한 값을 지정하고, 각각의 칼럼명 길이(var_len)는 4가 되도록 정의하였다. 칼럼명을 담을 col_list는 for문 전에 정의하여 for문이 실행될 때 리셋되지 않게 하였다.
string.ascii_uppercase는 'A~Z'까지 대문자를 나타내게 하고 random.choice를 이용하여 그중에 한 개를 선택한다. '+=' 연산자를 이용하여 랜덤으로 선택된 영어 대문자를 str_temp에 추가하면서 총 4개의 임의 알파벳 조합을 하나의 칼럼명으로 만들어지게 된다. 이렇게 생성된 4개 길이의 칼럼명을 append를 통해 col_list에 추가한다.
col_no = 10
var_len = 4
col_list = []
for i in range(col_no):
str_temp = ""
for j in range(var_len):
str_temp += random.choice(string.ascii_uppercase)
col_list.append(str_temp)
파일을 총 10개만 만들 예정이어서 file_no에 10을 입력하였다. for문의 'i'값을 이용하여 생성될 파일명을 작성하려고 range의 시작을 1로 하였다. 만일 range(file_no)로 하면 파일명을 0~9까지 만들어질 것이다.
이번 코드에서 중요한 것은 np.random.randint 이다. 10개 칼럼과 1000개의 행을 갖는 데이터 프레임을 만들기 위해 그 안에 들어가는 데이터를 생성하는 역할을 해 준다. 해당 함수를 이용한 결과 값은 array type으로 생성된다. 해당 함수 내에서 사용한 인자는 아래에 설명을 해 두었다.
- 100 : 얼마 범위 내의 int값을 랜덤으로 생성할 것인가를 지정.
100으로 지정하면 0~99 사이의 값, 10이면 0~9까지의 값을 만들어 낸다.
- size : (행의 개수, 열의 개수)
데이터 프레임을 생성하기 위해 pd.DataFrame을 사용하였다. 일반적으로 pd.DataFrame(array)로 만들어지고 columns 인자를 통해 사용자가 원하는 칼럼명을 입력할 수 있다.
끝으로 이렇게 생성된 데이터 프레임은 .to_csv를 이용하여 파일로 만든다. 나는 주로 프로그램 폴더 내에 'data'폴더를 따로 두고 데이터 파일들을 해당 폴더에서 관리하기 때문에 '.\\data\\'를 파일명 앞에 추가하여 경로를 지정했다.
i는 int 값이기 때문에 str()를 이용하여 string으로 변경하고 '.csv'를 붙여 최종 파일명을 만들었다.
to_excel를 사용하려면 '.xlsx'를 붙이면 된다. 끝으로 to_csv 내 인자로 index=False는 데이터 프레임의 인덱스를 파일로 변환할 때 사용할 것인지를 설정하는 것이다. 만일 True로 설정하게 되면 추후 해당 파일을 파이썬으로 불러올 때 인덱스 칼럼이 추가된다.
file_no = 10
for i in range(1, file_no+1):
data_no = 1000
data = pd.DataFrame(np.random.randint(100, size=(data_no, len(col_list))), columns=col_list)
data.to_csv('.\\data\\'+str(i)+'.csv', index=False)
지금까지 설명한 내용의 결과물에 대해 아래와 같이 정리해 보았다.
2. 데이터 파일 경로 내 파일명 불러오기
파일명을 확인하는 방법은 2가지로 설명을 하겠다. 사용하는 라이브러리는 'os'와 'glob'이다. 초기에는 glob만 사용했는데, 최근에는 폴더명과 파일명을 따로 관리하는데 유리한 os를 사용하고 있다. 라이브러리 import는 아래와 같이 하자.
from glob import glob
import os
file_path에 데이터가 저장되어 있는 폴더 경로를 입력하자. 프로그램이 저장되어 있는 기본경로 내에 data파일을 두고 있는 경우에는 '../data/' 또는 '.\\data\\'로 입력하면 된다. '/'와 '\\' 모두 경로에 사용하는 구분자이지만 '\\'로 사용하는 것을 권장한다.
os를 이용하는 방법은 listdir() 안에 file_path를 입력하면 되고, glob의 경우에는 추가 조건을 붙여서 사용한다. 'xslx' 과 'csv'가 폴더 내에 같이 있는 경우에 os는 모두 불러와야 하지만 glob은 '*.csv'를 사용하여 csv만 갖고 올 수 있다. listdir()을 사용할 경우 모든 파일명을 갖고 와서 추가 코딩을 통해 csv만 걸러 낼 수 있다. 나의 경우에는 코드가 조금 길어지지만 향후 관리 측면에서 listdir()을 많이 사용하고 있다.
file_path = '.\\data\\'
file_name_os = os.listdir(file_path)
file_name_glob = glob(file_path+'*')
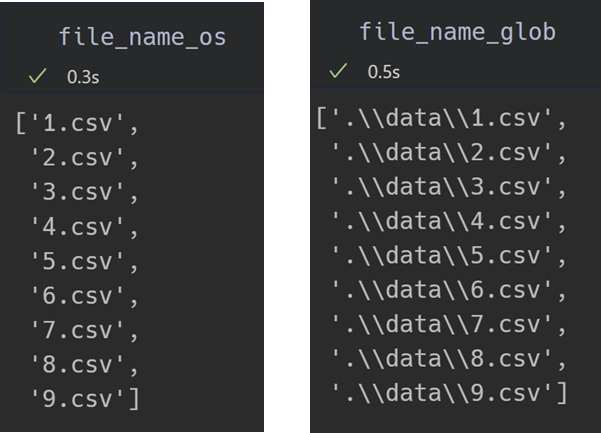
파일명을 불러온 결과를 보면 os는 파일 경로 내의 파일명만 정확히 불러온다. 하지만 glob의 경우 파일경로도 같이 불러오기 때문에 폴더와 파일을 따로 관리하는데 약간이 애로사항이 발생한다. 이후에는 os를 이용한 방법만을 설명하도록 한다.
3. 폴더/파일명을 이용한 여러 개의 파일의 데이터 취합하기
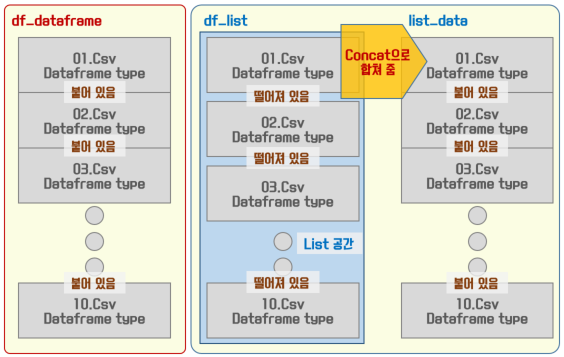
여기서도 두 가지 방법으로 설명하려고 한다. 라이브러리 차이가 아니라 사용방법의 차이에서 방식이 바뀐다. 불러온 데이터는 데이터 프레임 타입이 된다. 이때, append를 이용하여 처음에 불러온 데이터 프레임을 확장하며 다음 데이터를 붙이는 방법과 여러 개의 파일을 각각의 데이터 프레임으로 불러와서 마지막에 merge하는 방식이다. 이 두 가지 방법을 구분한 이유는 속도와 메모리 측면에서 비교를 위함이다. 데이터 파일 개수가 적고 데이터의 양이 많지 않다면 둘 중 아무거나 선택해서 사용하면 된다. 하지만 데이터의 양이 많을 때에는 append를 사용하게 되면 메모리의 양이 늘어나며 속도에 영향을 미치게 된다. 이제부터 해당 내용을 살펴보도록 하자.
df_dataframe = pd.DataFrame()
for fn in file_name_os:
df_dataframe = df_dataframe.append(pd.read_csv(file_path + fn))
dataframe에 데이터를 계속 추가하는 방식이다. pd.DataFrame()으로 빈 데이터 프레임을 정의하고 파일을 읽을 때 정의된 데이터 프레임에 append를 이용하여 데이터를 추가하는 방식이다. 해당 방식은 파일을 읽고 데이터를 추가한 후에 내용을 유지하고 있어야 하기 때문에 데이터 양이 많을 경우에는 메모리 점유율이 올라가서 프로그램이 다운되는 현상이 발생하곤 한다.
df_list = []
for fn in file_name_os:
df_list.append(pd.read_csv(file_path + fn))
list_data = pd.concat(df_list)
df_list에 빈 리스트를 정의하고 각각의 파일을 각각의 dataframe으로 리스트에 보관해 놓는다. for문이 완료된 후에 한꺼번에 취합한다. 두 개 방식을 비교한 그림은 아래와 같다. 오른쪽이 좀 더 복잡해 보이지만 성능면에서는 좋다
4. 데이터 파일 만들기
이제는 제일 쉬운 부분이다. DataFrame에는 to_csv, to_excel 함수가 있어 해당 함수를 사용하면 데이터프레임을 엑셀파일로 생성할 수 있다. 아래 코드에서 첫 번째 줄은 프로그램 파일이 저장된 기본 위치에 'merged_data.csv'파일을 생성하는 것이고 두 번째 줄은 file_path 경로에 'merged_data.csv'를 생성하게 된다. 다른 경로를 원한다면 file_path 대신에 해당 경로를 써 주면 된다.
list_data.to_csv('merged_data.csv')
list_data.to_csv(file_path + 'merged_data.csv')
5. 마치며
파이썬을 이용하여 여러 개의 엑셀파일을 취합하는 방법을 정리해 보았다. 파일의 데이터가 많지만 내가 사용할 칼럼명이 정해져 있다면 파일을 읽을 후 reference 파일을 이용하여 해당 칼럼만 추출하는 방식으로 메모리 점유율 관리를 할 수 있다. 해당 내용은 아래 썸네일을 통해 확인할 수 있다.
https://lifelong-education-dr-kim.tistory.com/15
Python pandas로 csv, xlsx 불러오기 tip
현장에서 사용하는 데이터 분석을 위해서는 현장에서 얻은 데이터의 전처리 업무가 데이터 분석의 약 80%이상을 차지한다 해도 과언이 아니다. 인터넷상으로 구한 데이터셋은 일정한 포맷이
lifelong-education-dr-kim.tistory.com



