목차
본 포스팅에서는데이터를 불러오기 위해 csv나 xlsx파일을 호출할 때 사용할 수 있는 reference file 관리에 대해 설명하려 한다. 물론 이는 config 파일과도 유사하지만 초기 데이터 분석을 위한 약간의 팁 정도로 생각하면 될 듯하다. 우선 현장에서 얻은 데이터가 필요하여, 그와 유사한 형태의 데이터를 만들고, 그 데이터를 이용하여 오늘의 포스팅 주제에 대해 얘기하려 한다.
1. data.csv 만들기
우선 python 코드를 위해 아래의 라이브러리를 호출한다. 대부분은 다 아는 라이브러리겠지만, string과 random은 생소할 수 있으니 설명을 한번 하겠다. string은 문자열을 생성시키는 것으로 string.digits는 숫자 문자열, string.ascii_lowercase와 string.ascii_uppercase는 영어의 소문자와 대문자를 호출하게 된다. random은 호출한 문자열에서 임의의 문자를 선택하기 위해 사용한다.
import numpy as np
import pandas as pd
import string
import random
import matplotlib.pyplot as plt
100개의 데이터 종류(데이터 칼럼)를 생성하기 위해 string과 random을 사용한다.
data_column = []
for i in range(100):
column_name = ''
for j in range(4):
column_name += random.choice(string.ascii_uppercase)
data_column.append(column_name + '_data')
첫 번째 for문(i)은 100개의 칼럼을 생성하기 위한 것이고 두 번째 for문(j)은 각 칼럼명을 랜덤으로 만들기 위한 것이다. 4개의 칼럼명이 만들어지면 마지막에 '_data'를 추가하여 마치 sensor1_data, pressure_data라는 느낌을 주었다.
아래의 코드를 이용하여 최종(row = 5000, col =100) 데이터인 data.csv를 만들었다.
col_no = 100
row_no = 5000
data = pd.DataFrame(columns=data_column)
for i in range(len(data_column)):
data[data_column[i]] = round(np.random.normal(random.random(), random.random(), row_no), 3)
data.to_csv('data.csv', index=False)
2. data.csv에서 reference file 생성하기
1번의 작업은 data가 없었기 때문에 임의의 데이터 파일을 만들어 주는 과정이다. 이번 포스팅에서는 reference file 생성 및 관리기 때문에 2번부터 내용을 확인해도 무방하다.
read_data = pd.read_csv('data.csv')
col_name = read_data.columns
ref_df = pd.DataFrame(columns=['feature', 'Used'])
ref_df['feature'] = col_name
ref_df['Used'] = 1
ref_df.to_excel('ref_feature.xlsx', index=False)
위의 코드를 보면, 우선 'data.csv'를 읽고 read_data란 dataframe에서 column만 따로 col_name에 저장했다. ref_df를 새로 정의하고 feature에는 data의 column명을, 또 다른 칼럼에는 사용 유무를 확인하는 used를 설정하였다. 기본값으로 1을 설정하였고 이 데이터프레임을 ref_feature.xlsx파일로 저장하였다. index=False를 사용하지 않으면 A열에 index(0, 1, 2, ...)가 생성되니 꼭 False를 입력해서 추출하기 바랍니다. to_excel을 사용하기 위해서는 openpyxl 라이브러리도 필요하다(pip install openpyxl 실행)
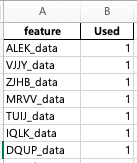
사실 2번 코드는 엑셀에서 작업해도 괜찮다. 다만, 수작업을 하다 혹시나 feature명이 틀릴 수 있는 오류가 발생하긴 하지만 금방 찾을 수 있다. 해당 참조 파일의 내용을 보면 알겠지만, 결국 Used의 값을 바꾸면서 데이터를 초기 생성할 때 사용할 feature만 불러오겠다는 것이다. 해당 방법이 편리한 이유는 데이터 분석(상관관계 분석, 데이터 특성 분석 등)을 하다 보면 raw data에서 그때그때 필요한 feature만 불러와서 사용해야 하는데, reference file의 수정만으로 가능하기 때문이다.
3. reference file을 이용하여 data.csv파일 호출하기
데이터 분석을 위해 데이터 파일(csv)과 reference file을 준비했으니 두 개의 파일을 이용하여 분석에 필요한 feature들만 호출해 보자. 본 포스팅에서는 reference file에서 위쪽에서 4번째까지만 사용해 보자
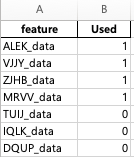
reference 파일을 호출하고 used에 1로 표기되어 있는 feature들을 list로 불러오는 코드를 아래에 작성하였다.
ref_data = pd.read_excel('ref_feature.xlsx')
ref_col = ref_data[ref_data['Used']==1]['feature'].to_list()
이후 데이터를 불러올 때 ref_col의 데이터만 들고 오면 된다.
ref_data = pd.read_csv('data.csv')[ref_col]
4. 마치며
매번 데이터 분석을 할 때마다 config 파일이나 코드 내의 칼럼명을 넣었다 지웠다를 반복하는 것을 목격한 나로서 데이터 분석을 하는 사람들에게 분석시간을 조금 더 단축하게 하고 싶은 마음에 본 포스팅을 작성하였다. 최근 포스팅에서 여러 개 엑셀 파일을 취합하는 내용을 다루었다. 현재 내용에 엑셀 파일 취합까지 효율적으로 한다면 데이터 분석에 많은 도움이 될 것이다. 엑셀 취합 포스팅은 아래에서 확인할 수 있다.
2022.05.14 - [공부 목록/IT & 프로그래밍] - Python 여러 개의 엑셀 파일을 하나로 취합하는 효율적인 방법
Python 여러 개의 엑셀 파일을 하나로 취합하는 효율적인 방법
회사업무를 하다 보면 여러 개의 엑셀 파일을 취합해야 하는 경우가 많이 생긴다. 특히나 데이터 분석에 필요한 데이터를 저장할 때 달, 주, 일, 시간 등 일정 단위로 파일을 생성하기 때문에 전
lifelong-education-dr-kim.tistory.com



